The electoral college is a disaster for a democracy.
— Donald J. Trump (@realDonaldTrump) November 7, 2012
I've recently been doing some work related to political affiliation and voter prediction for a friend who is starting a political advocacy organization. As a result, one thing that I have been thinking about a lot lately is predicting party affiliation for voter targeting. For example, can we use Twitter to figure out if folks are Democrats and target them for get-out-the-vote messaging accordingly?
I did a little bit of poking around on the web and found that predicting political affiliation based on Twitter data is a pretty challenging problem that traditionally has been approached in two ways:
- Parsing text of individuals' tweets to look for keywords
- Analyzing metadata (followers, followees, etc.)
Pennacchiotti and Popescu established in 2010 that the latter approach leads to higher accuracy results. Specifically, using only friends (i.e., who individual users follow on Twitter) can generate ~85% accuracy in predicting political affiliation, whereas text parsing coupled with a relatively sophisticated DLDA model does approximately 10 points worse.
What I found (full code and replication data here)
I decided to use a small set of well-known politicians and talking heads to divide users along ideological lines. The final model achieves an accuracy of ~90% in predicting a proxy for political affiliation. Predicting true political affiliation is likely harder, and the 90% accuracy would likely decrease by between 5-15% if we tested the model on a better indicator of political affiliation.
Generating the data
First, I built a small dataset of 250 Democrats and 250 Republicans by searching for users who tweeted "#ImWithHer" and "#MAGA." Note that this does not generate ideal ground truth test labels, as tweeting these slogans is not necessarily the same as being a Democrat/Republican. We would ideally like some sort of self-reporting tool to generate our test set (i.e., find users who self-identified as Democrats and Republicans), although, unfortunately, the popular tools for self-identification (e.g., www.wefollow.com) have been shut down over the last several years.
Next, I set out a standard list of 'followees', or politicians and celebrities we believe should strongly divide individuals along ideological lines. I used the Twitter API to determine, for each (follower, followee) pair, whether there is a relationship or not (binary indicator of 1 or 0). The full set of followees we include here is:
- Hillary Clinton
- Donald Trump
- Ted Cruz
- Elizabeth Warren
- Bernie Sanders
- Mike Pence
- Sean Hannity
Due to Twitter's delightful rate limiting policy, this data took almost a full day to gather. :dizzy_face:
Prediction
 {:height="280px" width="400px"}
{:height="280px" width="400px"}
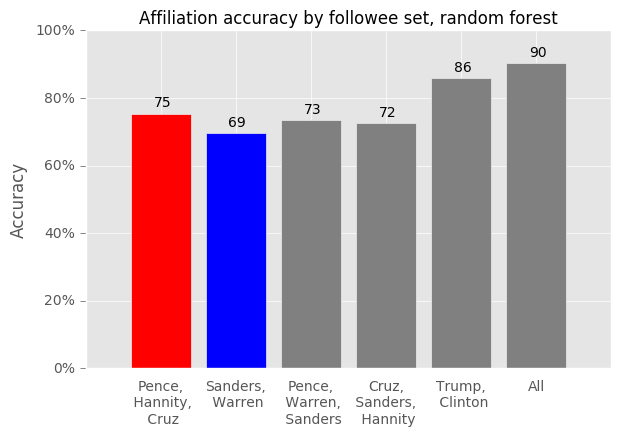
Random forest results
Finally, I tried out some real machine learning! I compared a couple of different approaches (kNN, logistic regression, random forest), tuned some parameters, and the results above were the best ones I got.
Discussion
Unsurprisingly, kNN performed substantially worse than the random forest and logistic regression models. The latter two models were nearly identical in their performance.
A few notes:
- The gray bars represent followee sets with a mix of political affiliations. Excluding Trump/Clinton, classifiers trained on these followee sets do not perform substantially better than classifiers trained on Democrat-only or Republican-only followee sets
- Classifiers trained only on Trump and Clinton as followees perform quite well (at 86%). This is unsurprising given the outcomes we are trying to learn (tweeting #ImWithHer and #MAGA)
- The very best classifiers are those that include all of the politicians, although we get only a 4 percentage point kick from adding in other followees on top of Trump and Clinton
- A potential next step here would be to use Amazon Mechanical Turk to hand-label ~1000 users and build a more robust test set (get real self-reported affiliations and see how the algorithm does)